How to split your dataset into train, test, and validation sets?
In a single line of code!

AI Engineer by the day . . . Batman by Knight!
Introduction
If you’ve been using the train_test_split method by sklearn to create the train, test, and validation datasets, then I know your pain.
Splitting datasets into the test, train, and validation datasets
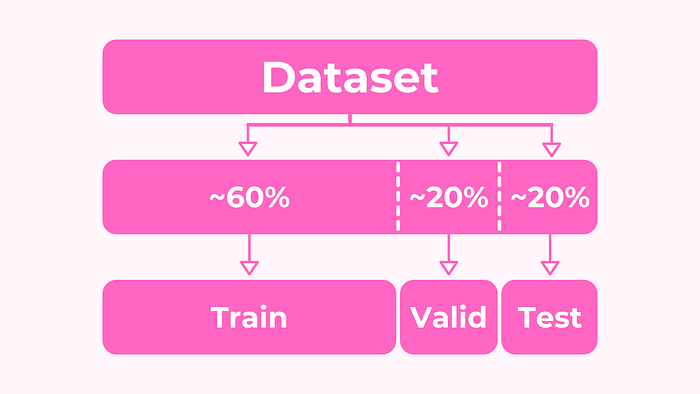
While sklearn certainly provides us with a way to achieve our objective, however, it is a long-drawn-out procedure as we have to repeat the process twice adjusting the split ratio with every step.
But rejoice, fast_ml is here!
It offers a straightforward and to-the-point method to achieve the three different datasets with a single line of code.
It is the train_valid_test_split method!
It not only splits the data as we require but also separates the dependent variable y from the independent variables X in the same line of code.
Code walkthrough
Let’s check out how it’s done (notebook)!
Step 1: Download the fast_ml library and Import the necessary packages and methods

Step 2: Load the dataset into a pandas data frame.

Step 3: Split the dataset
Once the data is loaded and ready to split, simply call the train_valid_test_split method and pass the dataset with the supporting parameters as below.

The datasets have been successfully split into train, test, and validation datasets. 🎉
💡 NOTE
The split datasets retain their original index and resetting it is an optional step.
You can now proceed with your modeling.
Conclusion
Thanks to the team at fast_ml, the long-drawn-out task of splitting our dataset into independent and dependent features and then into training, testing, and validation datasets has been condensed into a single line of code. ⚡
You can find this notebook here:
Let me know how you liked this quick article in the comments below, and feed free to reach out!